What is Tokenization and why it matters
When you type a sentence into ChatGPT, it doesn’t see the sentence as you do. Instead, it breaks the text down into smaller pieces called tokens. Tokens are the building blocks of large language models. They are what atoms are to elements.
Example:
Sentence -> "I love swimming"
Tokens -> "I", "love", "swim","ming".
How long or short tokens are depends on the specific tokenization method used. They can be as short as a single character or as long as a whole word.
These variation in token length matters because it affects:
- How much text fits in a model’s context window: Think of AI’s memory as a chalkboard, it can only fit a certain number of texts at time and if you keep writing, the old stuff has to get erased. That’s the same way AI “forgets” earlier parts of long conversations. It might still be able to generalize from the context but only upto a certain point.
The context window size of the LLMS have been been increasing over time in an attempt to increase working memory . For example, GPT-3.5 has a context window of about 4,000 tokens(roughly 3,000 words), while GPT-4 Turbo can handle up to 128,000 tokens (about 100,000 words). - How fast the model runs: Inside an LLM, every token has to “look/attend” at all the other tokens (like every student checking with every other student’s work in class). So, the more tokens there are, the more “checks” the model has to do. This means that if you double the number of tokens, you more than double the amount of work the model has to do making it slower
- How much it costs to use the model: Most LLMs charge based on the number of tokens processed. So, if your text is broken down into many small tokens, you might end up paying more than if it were broken down into fewer, larger tokens.
Graph below show how different tokenization strategies affect token counts and by extension, how fast an LLM runs.
Click to view code
import tiktoken
from nltk.tokenize import word_tokenize
import matplotlib.pyplot as plt
import seaborn as sns
# Sample text
text = """As far as I'm aware, you cant arbitrarily increase the context
length because its limited by how the model was trained.
More horsepower on your end isn't going to help anything because even
if you can exceed the context length, it just starts to lose
coherence because the model isn't trained to understand the longer context."""
# 1. Word-level tokenization (NLTK)
word_tokens = word_tokenize(text)
len_word = len(word_tokens)
# 2. Subword (BPE) tokenization (OpenAI GPT-3.5/4 tokenizer)
enc = tiktoken.encoding_for_model("gpt-3.5-turbo")
subword_tokens = enc.encode(text)
len_subword = len(subword_tokens)
# 3. Byte-level tokenization
len_byte = len(text.encode("utf-8"))
# Runtime scaling (O(n^2))
scaling = {
"Word-level": len_word**2,
"Subword (BPE)": len_subword**2,
"Byte-level": len_byte**2,
}
sns.set_style("whitegrid")
colors = sns.color_palette("pastel")
plt.figure(figsize=(8,6))
bars = plt.bar(scaling.keys(), scaling.values(), color=colors)
# Add value labels on bars
for bar, (label, value) in zip(bars, scaling.items()):
plt.text(
bar.get_x() + bar.get_width()/2,
bar.get_height(),
f"n={int(value**0.5)}",
ha="center", va="bottom", fontsize=11, weight="bold"
)
# Titles & labels
plt.title("Tokenization and Relative Runtime Complexity (O(n²))", fontsize=12, weight="bold")
plt.ylabel("Operations (n²)", fontsize=10)
plt.xlabel("Tokenization Type", fontsize=10)
plt.yscale("log")
plt.tight_layout()
plt.show()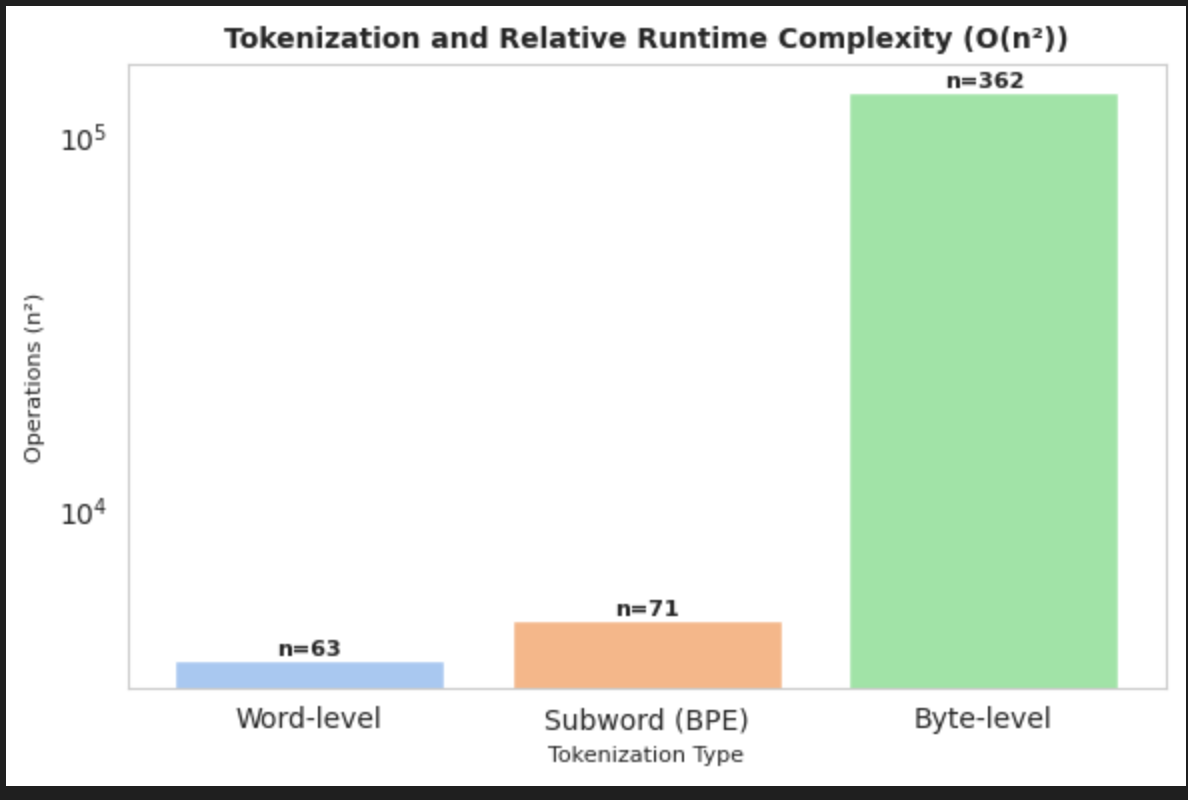
Byte-level explodes quickly → meaning much slower & more memory hungry for long texts
Balancing Token Size, Vocabulary, and Memory
From the above examples it can be easy to assume that using larger tokens (like whole words) is always better because it reduces the number of tokens and speeds up processing. However, it’s not that simple. There’s a trade-off between token size, vocabulary size, and memory usage.
Vocabulary size refers to the total number of unique tokens that the model recognizes. A larger vocabulary can capture more nuances of language but requires more memory to store and manage. Conversely, a smaller vocabulary is easier to handle but may miss out on important details.
- Large Tokens (Whole Words)
- Vocabulary: Huge (hundreds of thousands of words). This leads to big embedding tables and hence more memory per model
- Memory use: More efficient per sentence (fewer tokens).
- Problem: Can’t handle new words or misspellings.
- Example: If “fintechify” isn’t in the vocab, the model won’t know it
- Small Tokens (Characters/Bytes)
- Vocabulary: Tiny (just letters or byte values).
- Memory use: Very inefficient because sentences are explode into thousands of tokens. Uses more compute and RAM when running.
- Problem: Too slow for long texts.
- Example: “Nancy” → 5 tokens instead of 1.
- Balanced Approach: Subwords (BPE, SentencePiece)
- Vocabulary: Medium-sized (30k–50k tokens).
- Memory use: Efficient balance. Not too few, not too many tokens.
- Benefit: Can handle both common words as single tokens and break down rare/new words.
- Example: “fintechify” → “fin”, “tech”, “ify”.
For a balanced approach, subword tokenization methods are used in all the major LLMS today. These methods break down words into smaller meaningful chunks, allowing the model to handle a wide range of vocabulary while keeping memory usage manageable. The subword tokenization methods used include:
- Byte Pair Encoding (BPE): Used in models like GPT-2 and GPT-3. It starts with individual characters and iteratively merges the most frequent pairs to form subwords.
- SentencePiece: Used in models like T5 and ALBERT. It treats the text as a sequence of characters and uses a unigram language model to generate subwords.
- WordPiece: Used in models like BERT, DistilBERT, and Electra. It builds subwords based on the likelihood of word sequences, allowing for efficient handling of rare words.
For details you can checkout this tutorial post by Hugging Face.
Why Tokenization Matters
Tokenization is a very crucial step in the process of building and using large language models. If not done properly, it can lead to poor model performance and increased costs. Many LLM issues that most people think results from neural network training problems or model architecture problems are actually tokenization problems.-
- Why can’t LLMs spell words correctly?: LLMs work with tokens, which are chunks of text (a word, part of a word, or even a single character). Example: The word “unbelievable” might be split into tokens like [“un”, “believ”, “able”]. So the model doesn’t learn whole words and their spelling — it just learns patterns of tokens.
- Why can’t LLMs do simple arithmetic? The model might see “12345” as two tokens: [“123”, “45”]. So when you ask it to add “12345” and “67890”, it’s actually adding 123 + 45 + 678 + 90 = 936.
- Why do LLMs perform poorly on certain languages or dialects? - Dialtects or less common languages might have many words that aren’t in the model’s vocabulary. They also get to broken down into many more tokens for there equivalent text in English. This means the model has less context to work with and struggles to generate coherent responses. For example, a single word in a dialect might require 4–5 tokens, while the equivalent English word might only be 1. This makes the same sentence “longer” in terms of tokens, leaving the model with less usable context and more fragmented information to work with -Why GPT2 perfomed poorly python coding tasks? - GPT-2’s BPE tokenizer didn’t treat (\t) tabs indentations as single tokens. Each space was its own token hence bloating up the token count and reducing the effective context window for coding tasks. This was fixed in later models like GPT-3.5 and GPT-4 where each indentation level is a single token.
Try it out
To bring all these to life, lets see tokenization in action.
1. This tiktoken web app shows you tokenization in the browser.
Python code tokenization
-
In the example below GPT-2 beaks down the same code to 108 tokens while GPT-4 uses only 68 tokens. This is because of how they treat the indentations. Each token is represented as a colored block, and you can see that GPT-2 splits the indentation spaces into separate tokens, while GPT-4 treats each indentation level as a single token.
-
This means GPT-4 can handle much longer code snippets within the same context window and also run faster and cheaper.


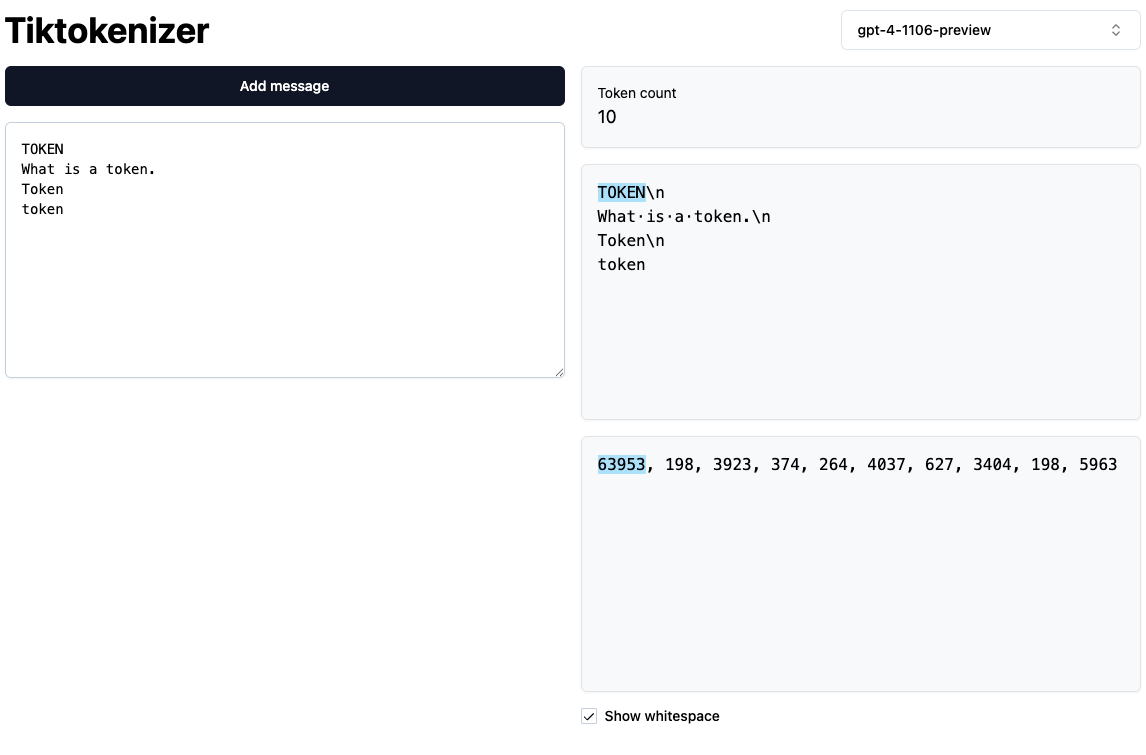
Tokenization of capitalzed and lowercase
- In the example below we see how GPT-4 tokenization treats capitalized and lowercase words differently. Despite them being the same word, they are tokeized differently depending on the casing. The model has to learn during training that
Tokenandtokenare the same word or different depending the context they are used in.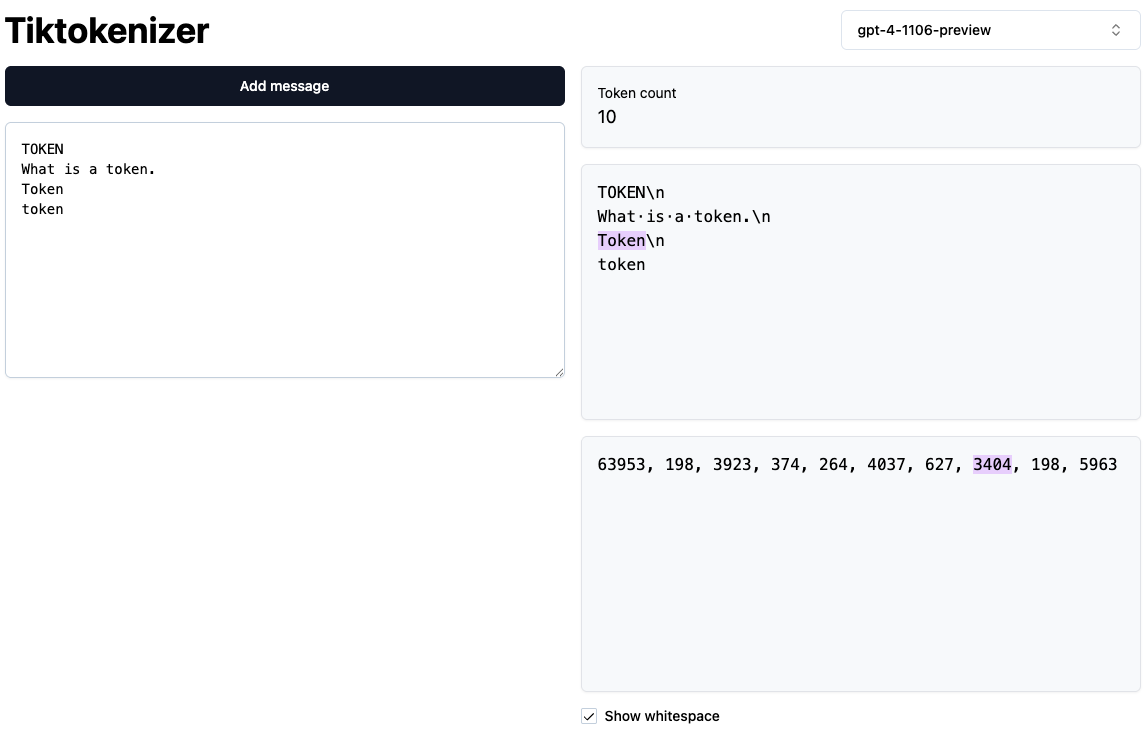
 2. OpenAI Tokenizer: You can use OpenAI’s tokenizer tool to see how different models tokenize text. OpenAI Tokenizer
2. OpenAI Tokenizer: You can use OpenAI’s tokenizer tool to see how different models tokenize text. OpenAI Tokenizer
I also built a simple Token Cost Calculator you can try out. Just paste or upload any text, and it will show you how many tokens it uses across different GPT models, how much it would cost, and whether it fits within each model’s context window. It’s a quick way to see how tokenization directly impacts cost, speed, and memory in practice. token calculator
Why it matters for the future
As context windows grow and tokenization strategies evolve, the efficiency of tokenization will directly influence how far LLMs can scale, not just in speed and cost, but in how well they handle diverse languages, dialects, and coding tasks.